
10·
1 month ago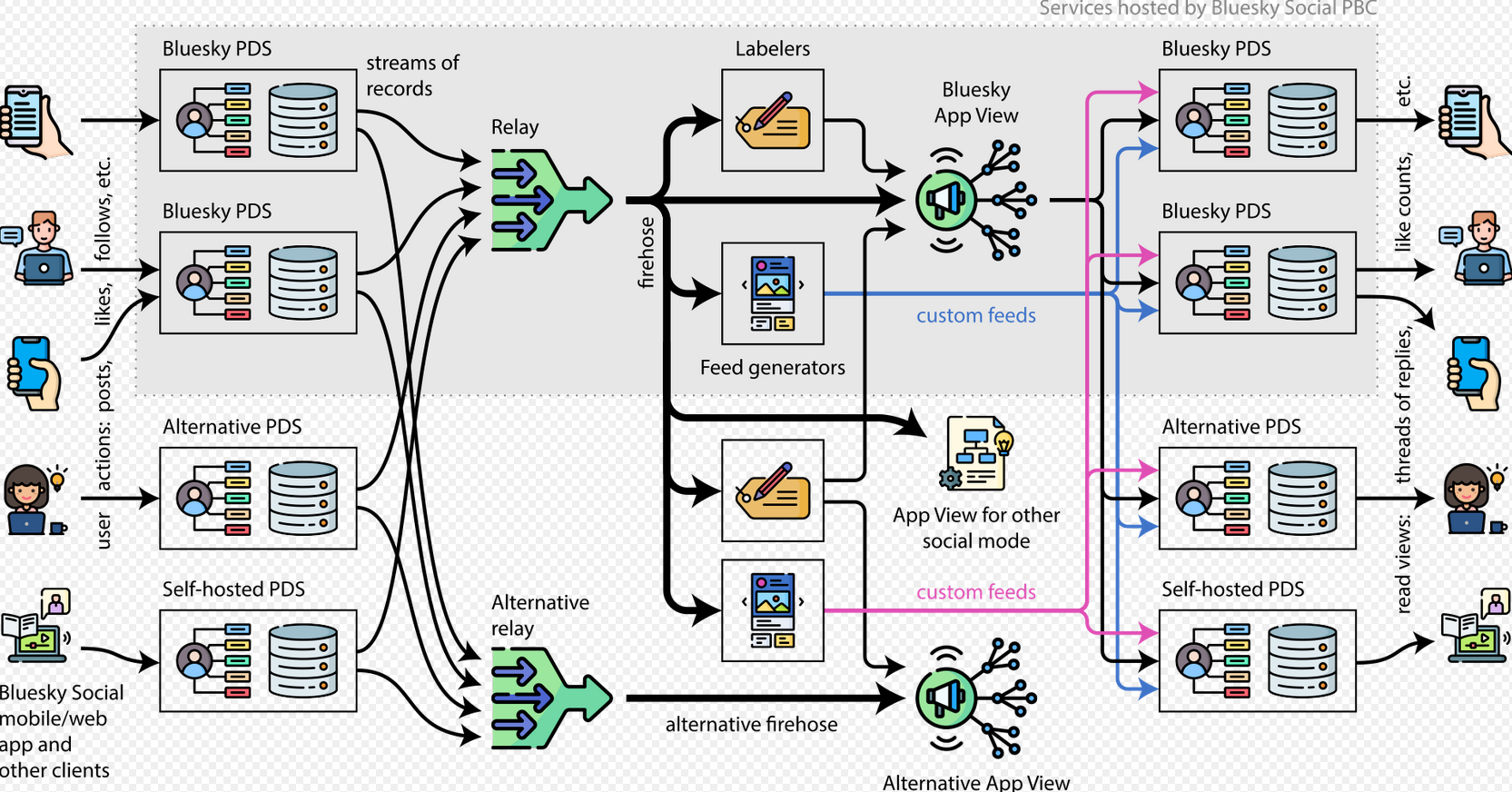
https://linktr.ee/tomawezome Donations:
You can run your own relays, the obstacle is that each relay takes up many terabytes. But it’s fully open.
https://github.com/bluesky-social/pds
https://whtwnd.com/bnewbold.net/entries/Notes on Running a Full-Network atproto Relay (July 2024)
https://news.ycombinator.com/item?id=42094369
https://docs.bsky.app/docs/advanced-guides/firehose
https://docs.bsky.app/docs/advanced-guides/federation-architecture#relay
Mobile games are designed like junk-food: take it out, eat some junk, then put it away to go do something else, throw away the bag or seal it for a quick snack later. Normal games are designed like a full meal: sit down somewhere with good atmosphere, nutritious, good conversation, get full and go home with plenty of leftovers and good memories
TinyLLM on a separate computer with 64GB RAM and a 12-core AMD Ryzen 5 5500GT, using the rocket-3b.Q5_K_M.gguf model, runs very quickly. Most of the RAM is used up by other programs I run on it, the LLM doesn’t take the lion’s share. I used to self host on just my laptop (5+ year old Thinkpad with upgraded RAM) and it ran OK with a few models but after a few months saved up for building a rig just for that kind of stuff to improve performance. All CPU, not using GPU, even if it would be faster, since I was curious if CPU-only would be usable, which it is. I also use the LLama-2 7b model or the 13b version, the 7b model ran slow on my laptop but runs at a decent speed on a larger rig. The less billions of parameters, the more goofy they get. Rocket-3b is great for quickly getting an idea of things, not great for copy-pasters. LLama 7b or 13b is a little better for handing you almost-exactly-correct answers for things. I think those models are meant for programming, but sometimes I ask them general life questions or vent to them and they receive it well and offer OK advice. I hope this info is helpful :)


